Spark architecture
This section describes how the Backend architecture is implemented in Spark Streaming.
Data Flow Graph
Bullet Spark implements the backend piece from the full Architecture. It is implemented with Spark Streaming:
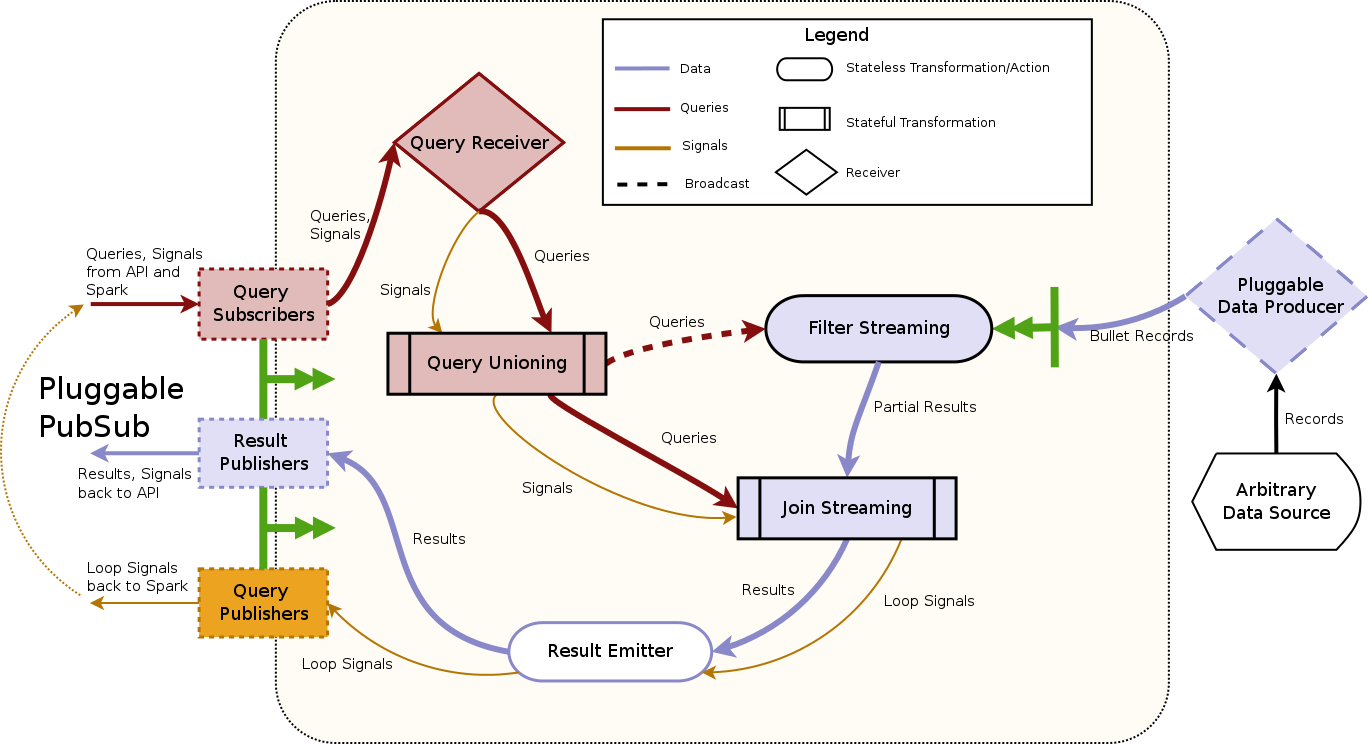
The components in the Architecture have direct counterparts here. The Query Receiver reading from the PubSub layer using plugged-in PubSub consumers and the Query Unioning make up the Request Processor. The Filter Streaming and your plugin for your source of data make up the Data Processor. The Join Streaming and the Result Emitter make up the Combiner.
The red lines are the path for the queries that come in through the PubSub, the orange lines are the path for the signals and the blue lines are for the data from your data source. The shapes of the boxes denote the type of transformation/action being executed in the boxes.
Data processing
Bullet can accept arbitrary sources of data as long as they can be ingested by Spark. They can be Kafka, Flume, Kinesis, and TCP sockets etc. You can either use DSL or hook up your data directly to Bullet Spark. To do the latter, you just need to implement the Data Producer Trait. In your implementation, you can either:
- Use Spark Streaming built-in sources to receive data. Below is a quick example for a direct Kafka source in Scala. You can also write it in Java:
import com.yahoo.bullet.spark.DataProducer
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
// import all other necessary packages
class DirectKafkaProducer extends DataProducer {
override def getBulletRecordStream(ssc: StreamingContext, config: BulletSparkConfig): DStream[BulletRecord] = {
val topics = Array("test")
val kafkaParams = Map[String, AnyRef](
"bootstrap.servers" -> "server1, server2",
"group.id" -> "mygroup",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[ByteArrayDeserializer]
// Other kafka params
)
val directKafkaStream = KafkaUtils.createDirectStream[String, Array[Byte]](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, Array[Byte]](topics, kafkaParams))
directKafkaStream.map(record => {
// Convert your record to BulletRecord
})
}
}
- Write a custom receiver to receive data from any arbitrary data source beyond the ones for which it has built-in support (that is, beyond Flume, Kafka, Kinesis, files, sockets, etc.). See example.
To use DSL, you can enable it by providing the bullet.spark.dsl.data.producer.enable: true and configuring the various DSL parameters.
After receiving your data, you can do any transformations like joins or type conversions in your implementation before emitting to the Filter Streaming stage.
The Filter Streaming stage checks every record from your data source against every query from Query Unioning stage to see if it matches and emits partial results to the Join Streaming stage.
Request processing
The Query Receiver fetches Bullet queries and signals through the PubSub layer using the Subscribers provided by the plugged in PubSub layer. The queries received through the PubSub also contain information about the query such as its unique identifier, potentially other metadata and signals. The Query Unioning collects all active queries by the stateful transformation updateStateByKey and broadcasts all the collected queries to every executor for the Filter Streaming stage.
The Query Unioning also sends all active queries and signals to the Join Streaming stage.
Combining
The Filter Streaming combines all the partial results from the Filter Streaming by the stateful transformation mapWithState and produces final results.
The Result Emitter uses the particular publisher from the plugged in PubSub layer to send back results/loop signals.